Pivot tables es una funcionalidad que suelen ofrecer los programas de hojas de calculo (MS Excel, LibreOffice Calc, etc.)
Es una herramienta para resumir datos (data summarization) desde una base de datos. Resulta muy cómodo para contar lineas en una hoja de calculo donde hay un patrón similar o para sumar números que pertenecen en una categoría.
Un ejemplo se puede ver en la entrada de wikipedia sobre los pivot tables.
AWK
Awk es un programa que permitir procesar texto. Nos permite acceder linea por linea cualquier archivo de texto y hacer operaciones sobre ellas. Es una herramienta algo mas complicada, ya que se utiliza a través de la linea de comandos. Entiende un lenguaje basado en bash y C++. Para entender la posibilidades que nos ofrece a la hora de procesar archivos de textos, podemos mirar la documentacion completa del programa awk
Los datos que estoy trabajando actualmente son gastos que hacen distintos departamentos de ayuntamientos españoles.
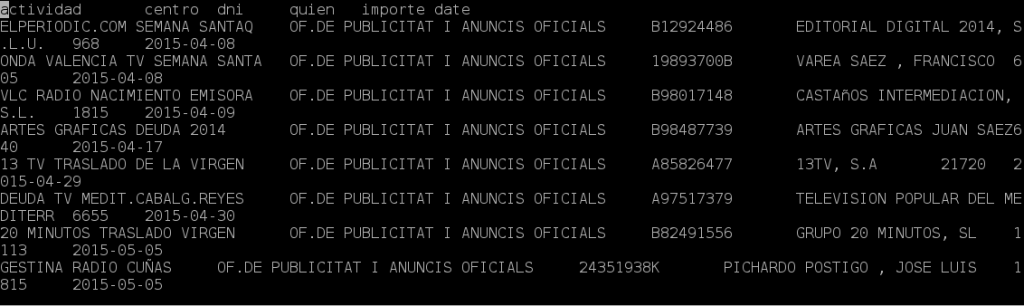
Se trata de un archivo TSV que tiene la siguiente forma
Actividad | centro | dni | quien | importe | date
Actividad : el concepto de contratos que hizo el ayuntamiento con una entidad
centro : El departamiento del ayuntamiento que realizo la actividad
dni : El DNI de la empresa o professional que realizo el contrato
quien : nombre de la empresa o professional o entidad que realizo el contrato
importe : importe en miles de euros
date : La fecha del contrato
Para el proyecto de visualización de datos en que estoy colaborando necesitamos resumir unos datos, como por ejemplo:
- El total de contratos realizados por la misma empresa
- El total del importe por cada empresa
- Los distintos centros de gasto
- resumen del tipo de actividad
Estos datos se guardan en tres archivos complementarios : thinglist.tsv, centroslist.tsv, viplist.tsv.
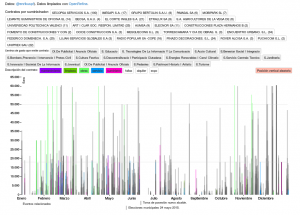
Estamos utilizando los pivot tables para generar estos resúmenes que luego integramos a nuestro gráfico que se puede ver aqui.
Ahora existe la intención de utilizar esa manera de visualizar los datos como una herramienta mas versatil que podria servir para visualizar cualquier cantidad en el tiempo. Faltan muchas cosas para definir si queremos darle forma de un programa de visualizacion de datos.
En esa direccion he pensado que tenemos que quitar la dependencia de programas externos (como Libreoffice Calc) que actualmente utilizamos para “preparar los datos” antes de lanzar la visualización. Utilizar awk en vez de Calc podria evitar hacer el trabajo manual que se esta haciendo cuando necesitamos visualizar unos datos.
He seguido un tutorial que explica como hacer pivot tables con awk y lo he adaptado para los datos de contratos menores.
Vamos a ver paso a paso como podemos generar los pivot tables.
Empezamos solo imprimiendo linea por linea el documento que contiene los datos
awk -F $'\t' ' {print}' data_val2015.tsv
aquí con el flag -F estamos diciendo a awk que las columnas de nuestro archivo esta separadas con tabulaciones $’\t’
En seguida podemos elegir imprimir solo unas columnas y no todas.
awk -F $'\t' ' {print $3, $5}' data_val2015.tsv

despues del print hemos precizado que queremos que devuelva solo la columna 3 y 5.
Luego para que podamos hacer operaciones matematicas necesitamos saltar la primera linea que contiene la descripcion de las columnas.
awk -F $'\t' ' NR>1 {print $3, $5}' data_val2015.tsv
Eso se hace con NR>1 (Number of Rows)
ahora las cosas empezaran a ser un poco mas complicadas.
awk -F $'\t' ' NR>1 {a[$4]++;} END {for (i in a) {printf ("%s\t%i\n"),i, a[i]}}' data_val2015.tsv
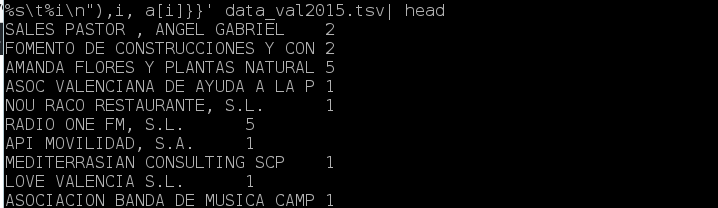
Primero nos fijamos que nuestro programa tiene dos mas pequeños, cada uno entre corchetes{} y separados con la palabra END.
Esto resulta que la ejecución linea por linea sera todo lo que encontramos entre los primeros corchetes y una vez finalizado el documento (es decir END) ejecute el otro programa que se encuentra entre corchetes.
En la primera parte un array a[] con índice el campo $4 (nombre de la empresa) estará contando las veces que se encuentra cada empresa. Una vez hecho, la repetitiva for() se encargara de imprimir una por una las empresas que están en los índices i, y al lado la cantidad guardada en el array a[].
Finalmente vamos a hacer una tabla con las siguientes columnas
empresa | num_contratos | total_importe | DNI
awk -F $'\t' ' NR>1 {a[$4]++; b[$4]+=$5; c[$4]=$3} END {for (i in a) {printf ("%s\t%i\t%i\t%s\n"),i, a[i], b[i], c[i]}}' data_val2015.tsv
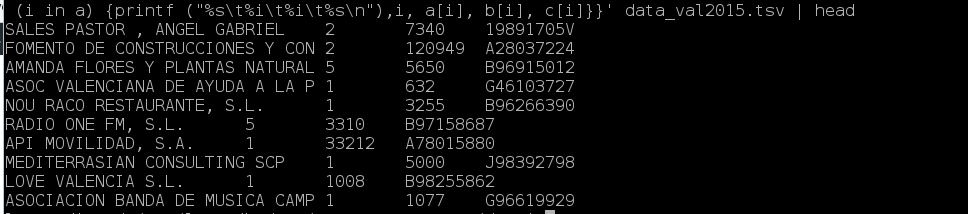
Igual que en el ejemplo anterior tres arrays a[], b[] y c[] estaran guardan respectivamente la suma de contratos con ++, la suma de importe con +=$5 y el DNI de la empresa que esta siempre en la columna 3.
La repetitiva for va a recorer todas las empresas y la printf se encarga de dar forma a los datos que vamos a imprimir. El sintaxis del printf es al estilo de C++.